We are happy to announce the launch of our new Emotion Analysis API!
This new API enables you to detect the emotions of a paragraph of text. In total, our API can identify 6 different emotions. Those are: happiness (joy), anger, sadness, disgust, surprise, and fear.
After analyzing the paragraph, our Emotion Analysis API indicates which of these 6 emotions were detected. You can see in the image below, that the API displays the strength of those emotions in form of emotion scores.
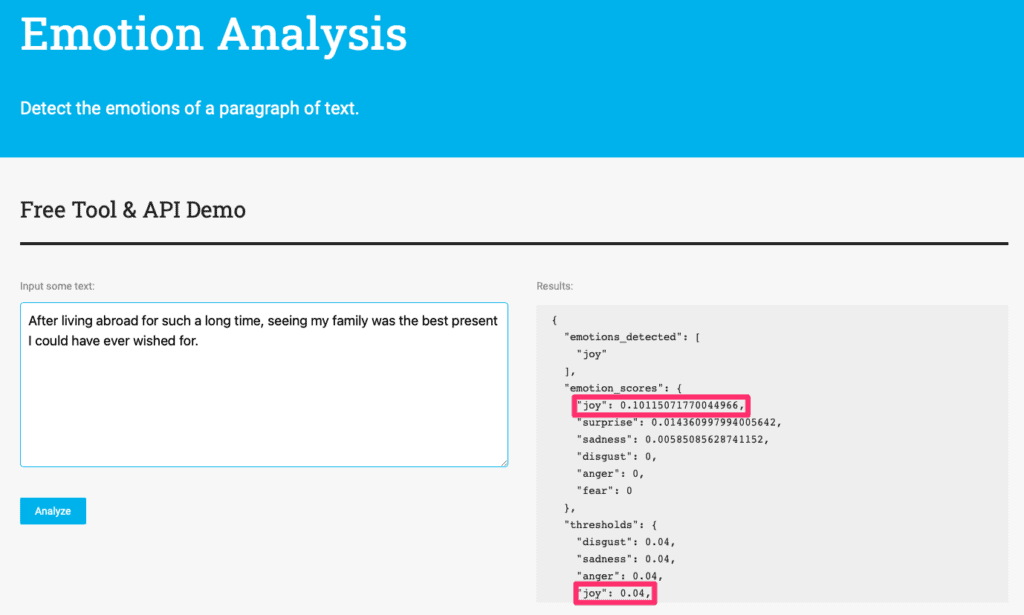
Regarding the thresholds, it’s just Twinword’s recommendation. Anything above a score of 0.04 we tag as emotion detected. In case you are not satisfied with the threshold of the Emotion Analysis API, you can simply ignore the result that the API returns, and choose to go with an adjusted threshold that works for your services. For example, you can decide that any score above 0.03 is emotion detected, and so on.
Why This API Is So Useful
As our world becomes increasingly digitalized, more and more people are interacting through digital platforms.
The detection of emotions in written text is a powerful tool that can be useful in several ways. For example, by understanding the emotions of your users you can easily measure and analyze User Experience and get to know your users in a completely new way.
With the help of our Emotion Analysis API you can even customize your app or website according to your user’s emotions.
For example, you could use our API to implement auto-suggested or pre-filtered emojis in messenger apps. In that way, users can easily find emojis that fit the emotion of their message.
Try It Yourself For Free!
Interested? You can try this API for free at our Emotion Analysis API Demo Page.
You can also consume the API directly via Amazon AWS Marketplace or RapidAPI Marketplace. Find more information on how to consume our API.


{kind=link}
{kind=link}
{kind=link}
1 Comment
I would really like to know the algorithm/approach you use to detect emotions. Is it simply lexically based (ie: count up emotion scores of words), does it use a NN trained on public emotion data? your own data? Does it use recent NLP developments like BERT?